Teradata Table Skew: Understanding Natural and Artificial Skew with DBC.TableSizeV

Teradata table skew is a common issue encountered while working with the Teradata database. If you're reading this page, you may have experienced this problem.
Common knowledge
When searching for Teradata table skew or skew factor online, most or all documentation will refer directly to DBC.TableSizeV for computation.
To analyze table skew, the commonly used query is:
Want more practical data engineering analysis like this?
Join DWHPro Letters and get field-tested notes on Teradata, Snowflake, AI, migrations, performance, and enterprise data work. DWHPro Letters is free. Subscribe to get new issues by email.
SELECT
DATABASENAME,
TABLENAME,
SUM(CURRENTPERM) CURRENTPERM,
CAST((100-(AVG(CURRENTPERM)/MAX(CURRENTPERM)*100)) AS DECIMAL(5,2)) AS SKEW_PCT
FROM DBC.TABLESIZEV
WHERE 1=1
AND DATABASENAME = 'db1'
GROUP BY DATABASENAME,TABLENAME ;Except that the result can be biased and mislead you!
How it can be misleading
You get a skew from this query based on how much space the data takes up per AMP.
There are two different things to consider :
- the natural skew: is what I call the skew produced by how data is distributed among the AMPs based on the table's Primary Index
- the artificial skew: is what I call the skew generated by the size of the data stored on each AMP
With the query above, you can find a table with a skew of 60%: we cannot conclude right away that this table has inadequate data distribution and needs a new PI...
…simply because our concept of skew (non-uniform distribution in a dataset) here is based not on the distribution of rows but on the size of the data per AMP.
A closer look
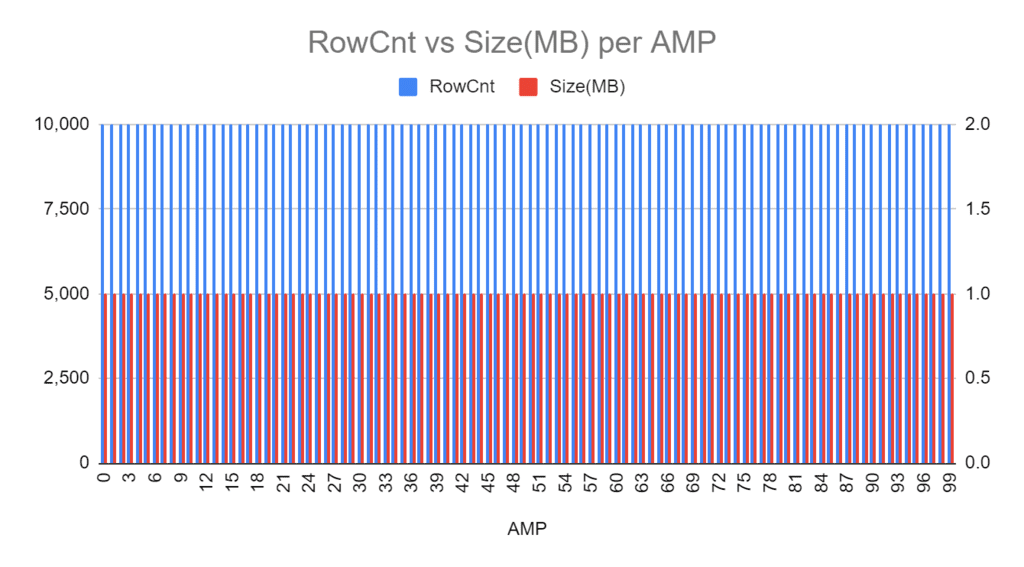
Suppose you have a 100 AMP system.
A table containing 1 million rows, perfectly distributed on all 100 AMPs (10,000 rows per AMP).
The size of these 10,000 rows is 1 MB on each AMP.
Based on the query above, there is 0 skew.
When using a particular compression type, the size of the data stored on the AMPs can change…!
I am talking about Temperature-Based Block Level Compression (TBBLC).
Get the next issue by email.
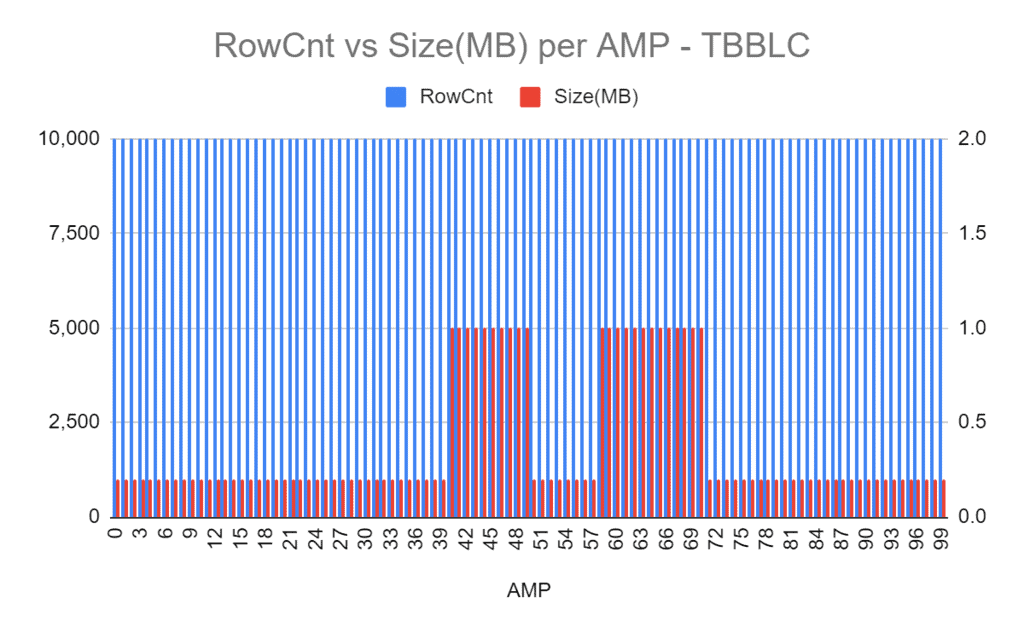
Same table as above, but this time-compressed in TBBLC. The skew is now at 63%.
Explanation
Not to get into the details of TBBLC and TVS, but this compression (TBBLC) works based on how frequently data is accessed:
- WARM/HOT data (frequently accessed data) is not compressed
- while COLD data (not accessed or less frequently accessed data) is compressed
Data in AMPs 0-39, 50-57, and 71-99 are compressed (from 1MB down to 0.2MB) - because they are tagged as COLD data.
On the other hand, data in AMPs 40-49 and 58-70 remain unchanged, still uncompressed at 1MB - because they are often accessed and tagged as WARM/HOT data.
Using the previous query, the skew went from 0% to 63% for the same table!
But not because the data distribution from the Primary Index (natural skew) has changed, but because of how the data is compressed on the AMPs (which I referred to as the artificial skew).
This is why identifying skewed tables based on this method is misleading.
Wrap-up
To investigate skewed tables using DBC.TableSizeV, verify whether the skew results from the primary index distribution or data compression.
The Teradata functions: HASHAMP, HASHBUCKET, and HASHROW can help you find this natural data skew:
HASHROW will give you the 4-byte row hash
HASHBUCKET will provide you with the bucket number in the hash map that holds this row hash
HASHAMP will provide you with the corresponding AMP that the hash bucket falls in
/*add TRANSACTIONTIME and-or VALIDTIME qualifier when analyzing temporal tables*/
SELECT
HASHAMP(HASHBUCKET(HASHROW( /*primary index columns*/ ))),
COUNT(*)
FROM databasename.tablename
GROUP BY 1
ORDER BY 1 DESC;As for TBBLC, as incredible as it may sound, you will need to know in advance how your data will be accessed to avoid huge differences in table size per AMP.
I hope this article has provided you with valuable insight on table skew.
Thanks for reading!
-Gerome Fournier
You may want to check out these articles related to skew!
The Impact of Skewing on Teradata demonstrated
One Of our Biggest Enemies: Skew In Teradata Joins
Planning or surviving an enterprise data platform migration?
I write regularly about the performance, cost, architecture, and project mistakes that show up in real Teradata, Snowflake, Databricks, and enterprise data work.
Subscribe for free and keep launch access.
Written by Roland Wenzlofsky, founder of DWHPro and author of Teradata Query Performance Tuning. DWHPro has helped data warehouse practitioners for 15+ years.