Teradata Unique Secondary Index: Everything You Need to Know
Learn about Teradata's unique secondary indexes (USI) and how they provide an alternate access path to reduce disk IOs while retrieving data. This article explains the technical differences between USI and other indexes, and provides detailed information on the data retrieval process. Discover how t

Teradata's Secondary Index offers an alternative means of accessing rows, minimizing disk I/Os during data retrieval.
Despite their widespread use in database systems, Teradata employs an alternative to B+ Tree Indexes.
Teradata categorizes secondary indexes into unique (USI) and non-unique (NUSI). Despite their similar names, they differ in functionality. The following article pertains solely to USI.
Unique secondary indexes use Teradata's hashing algorithm to distribute data evenly across disks. While technically tables, they are sub-tables and do not appear in dictionary tables like join indexes.
The primary index column(s) hash the base table data, whereas the secondary index rows are hashed by different columns or combinations of columns, providing an additional path for data.
The USI row includes the ROWID of the corresponding base table row, enabling a direct lookup of said row.
Access to Teradata USI is typically limited to 2 AMPs. Initially, a lookup is performed on the secondary index row, which includes the ROWID for the base table. This ROWID is then used to locate the base table row. Occasionally, the USI row and the base table row are situated on the same AMP, resulting in AMP-local retrieval of the base table row.
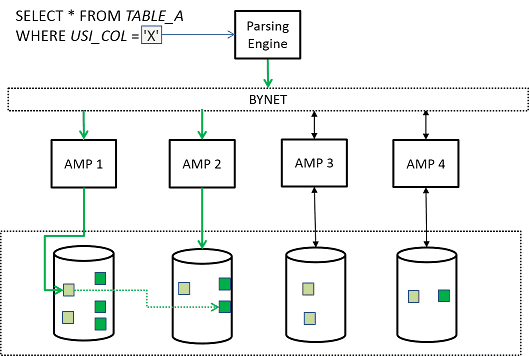
The unique secondary index distributes evenly across the AMPs, functioning as a distinct primary index, thus eliminating the issue of data skewing.
Teradata requires current statistics for evaluating index usage, particularly for highly selective USIs. Failure to meet this selectivity standard will likely result in Teradata not incorporating the index into the execution plan. Specifically, it will not be utilized if the number of table rows selected from the USI exceeds 10%. However, this 10% threshold should be considered a general guideline rather than a strict rule.
Typically, one would devise a preferred USI and verify its use through an EXPLAIN statement. If it is in use, retain it; otherwise, discard it. It is important to note that unique secondary indexes are physical tables that occupy disk space.
Information about the Teradata USI you will find nowhere else:
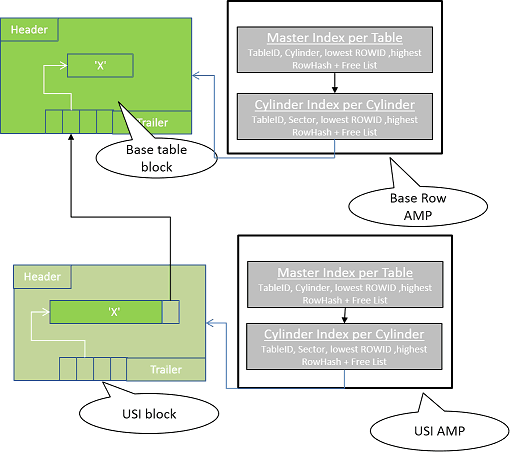
The meticulous process of retrieving data.
- The Parsing Engine consults the hash map and locates the AMP carrying the USI row.
- The AMP containing the USI row finds the USI data block via the Master Index & the Cylinder Index.
- The USI data block is moved into the FSG cache.
- The AMP does an in-memory binary search of the data block and locates the USI row.
- The designated row carries the ROWID of the base table. The Parsing Engine uses this ROWID to look up the base table AMP and instructs it to retrieve the base table row.
- The base table AMP locates the data block via Master Index & Cylinder Index lookup.
- The base table AMP moves the data block into the FSG cache.
- The base table row is located with an in-memory binary search on the base table block.
See also:
The Secondary Index in Teradata - The NUSI compendium
The Teradata Join Index Guide - We leave no questions unanswered!
The Teradata Partitioned Primary Index (PPI) Guide
Watch the Teradata Indexing Video Course