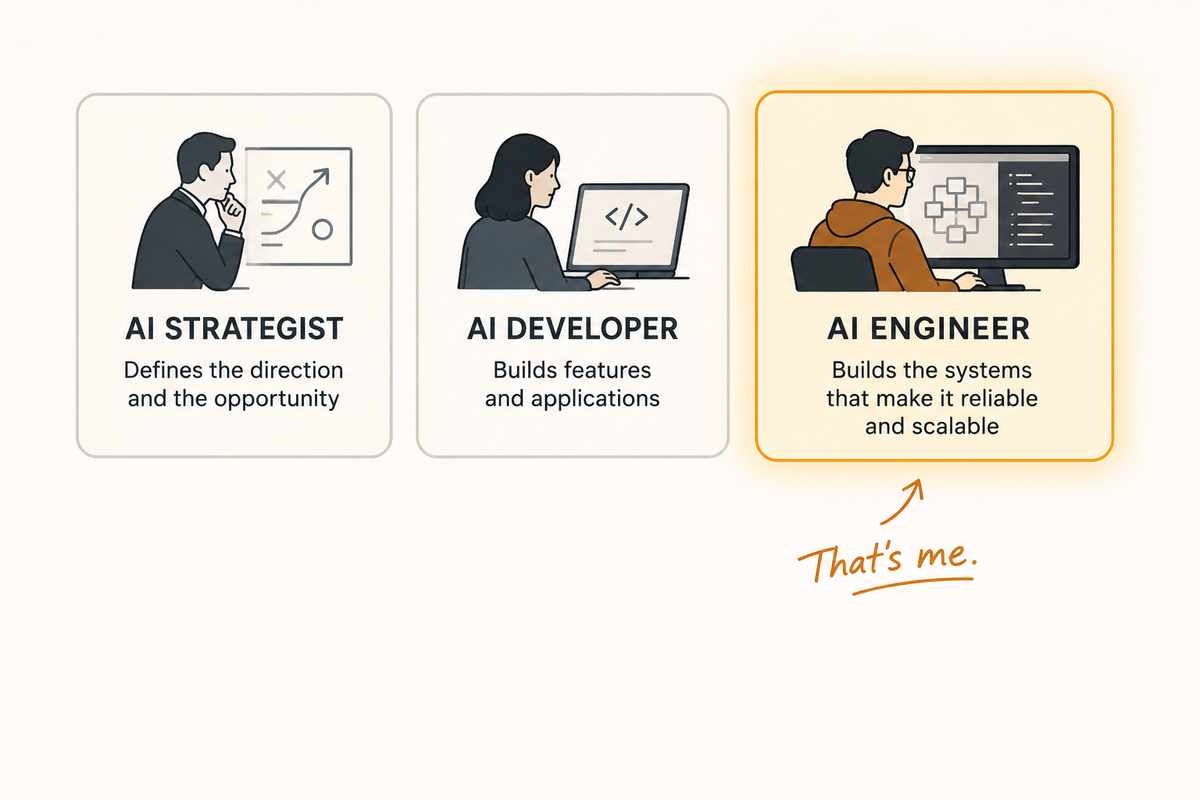
14 May 2026 Share From Data Engineer to AI Engineer: The Real Path This post is for subscribers only Subscribe now Already have an account? Sign in.