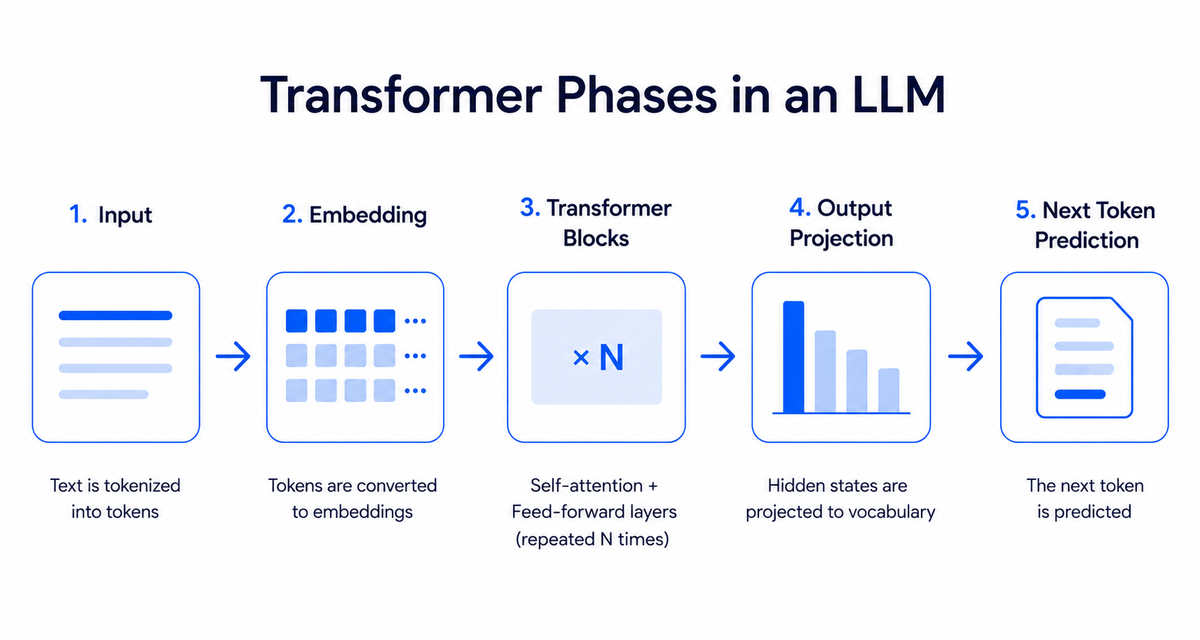
15 May 2026 Share What You Actually Need to Know About LLMs Before the Next Interview This post is for subscribers only Subscribe now Already have an account? Sign in.